
国产模型指令跟随全球第一!来自LeCun亲推的最难作弊LLM新榜单
What???
一直低调行事的国内初创公司,旗下模型悄悄地跃升成国内第一、世界第五(仅排在o1系列和 3.5之后)!
而且是前十名中的唯一一家国产公司。
(该榜上国产第二名是阿里开源的qwen2.572b,总榜第13)。
而且它登上的这个排行榜,虽然现在还没有大模型竞技场(LMSYS Arena)那么广为人知,但资格杠杠的——
图灵奖得主、Meta首席AI科学家杨立昆(Yann LeCun),联合纽约大学等在今年6月推出。
号称是“全球首个无法作弊的LLM基准测试”。

而这次冷不丁杀出来的黑马,其实比较熟悉国内大模型竞争格局的朋友们已经猜到了——
Step系列,背后是大模型六小虎之一的阶跃星辰。
指令跟随高分拿下全球第一
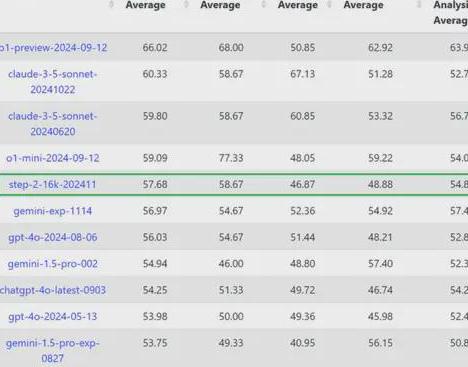
在榜单上,阶跃星辰自研的万亿参数语言大模型Step216k在 上拿下57.68分。
位列总榜第五、国产第一。
这个榜单之前出现频率不高,一方面是它确实很新,今年6月才刚推出;另一方面更加现实,那就是此前国产大模型并未在这个榜单塔尖取得傲人成绩。
这倒也不耽误榜单自身的实力——
LeCun和纽约大学等机构联手推出,专为大模型设计,目前包含6个类别的17个不同任务,每月更新新问题。
目标是确保榜单的问题不易受到污染 ,并且能够轻松、准确、公平地进行评估。
强调不易受到污染,是因为训练数据中包含了大量互联网内容,许多很容易受到污染。
比如大家比较熟悉的数学测试集GSM8K,最近被证明有好些模型已经在它这儿过拟合了。这显然为评估模型能力带来了困扰。
除了要小心被污染,确保评估方式公平、无偏见也很重要。
一般来说,大家都采用的是LLM担任评委或人类当裁判这两种方式。而选择采用客观、基本事实判断来评估每个问题。

那么,当我们首次正视这个榜单的时候,我们还能从其中看出些什么?
先说成绩出色的Step2。
IF 一项,也就是指令跟随,它以最高分拿下全球第一。
这个项目的内容,是对《卫报》近期新文章进行改写、简化、总结或生成故事。
86.57这个成绩是真的非常高——榜单上其余众人(哪怕是和家的模型们)都在7080分段,单项第二名的MetaLLaMA3.1405bturbo比它低了8分多。
这意味着,Step2在语言生成上对细节有强控制力,理解能力max,然后更好地遵循人类指令。
更具体些可以理解为,当我们普通人输入语句颠倒、语意不清、表意模糊的非专业·真普通·时,Step2能结合上下文、具体情境推断使用者的具体需求,把一个模糊指令从“360p”进行“1080p”的理解,精准捕捉模糊指令背后的真实意图。
同时意味着内容创作能力也很强,比如让它创作一首古诗词,它在字数、格律、押韵、意境等方面,都能有精准的把控。
完全自主研发,MoE架构,万亿参数
在这次因为又出来炸场一波之前,Step2留给外界的最深刻印象,一定有一个是“国内首个由初创公司推出的万亿参数大模型”。
这有点像阶跃风格的具像化。在大模型六小虎中,阶跃的Step系列发布最晚,但出手毫不含糊。
今年3月,Step2在全球开发者先锋大会开幕式预览亮相,一下子就从前作Step1的千亿参数规模,拉升到了万亿参数规模。
吊足了胃口后,夏天的WAIC 2024期间,Step2推出正式版。

模型采用了MoE架构。
一般而言,主流训练MoE模型有两种方式,不然就基于已有模型通过(向上复用)开始训练,不然就从头开始训练。
方式所需算力相对更低、训练效率更高,但随随便便就到这种方式的天花板了。
比如基于拷贝复制得到的MoE模型,非常容易出现专家同质化严重的情况。
而选择从头开始训练MoE模型的话,能够探得更高的模型上限,但作为代价,训练难度也会增大。
但阶跃团队还是选择了后者,选择完全自主研发,选择从头开始训练。
过程中,通过部分专家共享参数、异构化专家设计等创新MoE架构设计,Step2这个混合专家模型中的每个专家都得到了充分训练。
故而,Step2总参数量达到万亿级别,每次训练或推理所激活的参数量也超过了市面上的大部分Dense模型。
Step2的训练过程中,阶跃的系统团队突破了6D并行、极致显存管理、完全自动化运维等关键技术,支撑起了整个模型的高效训练。
初亮相时,阶跃*表示:
Step2在数理逻辑、编程、中文知识、英文知识、指令跟随等方面体感全面逼近GPT4。
结合这次 AI的成绩来看,团队对Step2的定位、优势所在,把握得很清晰。
基座模型技术能力强,关键是要让人用起来才行。
*消息是,Step2已经接入了阶跃星辰的C端智能生活助手「跃问」,Web端和App都可以试一把。
如果是开发者,可以在阶跃星辰开放平台通过API接入使用Step2。
语言模型和多模态模型全都要
开篇咱们提到,Step模型是一个系列,而Step2是其语言模型的实力代表。
在这个系列中,除了语言模型,阶跃星辰的多模态模型也很有看头。
Step1.5V是阶跃星辰的多模理解大模型,这款模型在三个方面优势突出:
一是感知能力。创新的图文混排训练方法,让Step1.5V能理解复杂图表、流程图、准确感知物理空间复杂的几何位置,还能够处理高分辨率和极限长宽比的图像。
二是推理能力。根据图像内容进行各类高级推理任务,如解答数学题、编写代码、创作诗歌等。
三是视频理解能力。它不仅能够准确识别视频中的物体、人物和环境,还能够理解视频的整体氛围和人物情绪。
生成方面,阶跃手里有Step1X图像生成大模型。
Step1X采用DiT( with )架构,有600M、2B和8B三种不同的参数量,语意理解和图像创意实现两手抓。
具体而言,不管文本指令简单还是复杂,不管是画单一对象还是多层次、复杂内涵场景,它都能cover。
另外,该模型还支持针对中国元素的深度优化,使生成内容更适合国人的审美风格。
至于语言模型和多模态模型全都要,阶跃有自己的道理。
从成立一开始,阶跃星辰就明确了自身通往 AGI 的路线图:
单模态——多模态——多模态理解和生成的统一——世界模型——AGI。
换言之,阶跃的目标是开发出能够实现AGI的多模态大模型,并利用这些自主研发的大模型,创造新一代的AI应用。
为着这个目标,这一年多来,阶跃已经写下了属于自己的答案。
研发迭代速度很快,不到一年,无论Step1到Step2, 还是Step1V到Step1.5V,整体持续跑步前进中。
产品也有自己的想法,没有局限在上。Step2登顶国内的同一天,阶跃旗下的跃问还上了一个新功能:
简单设置,就能通过 16右下方侧边的“相机控制”按钮,一键调用“拍照问”功能。
没有 16的苹果用户,把系统升级到iOS18也能一步调用国产AI 了。
虽然已经在六小虎中占据一席,但近日看阶跃,仍然想以黑马来形容它。
论技术和实力,Step2能突然杀到业界权威榜单国内第一,成为全球榜单前十唯一国产玩家。
大模型浪潮奔腾至今,已经有快两年的时间了。
两年里,投身其中的技术从业者们都在(看似分布其实共同)打造一个愿景,一个许多人都愿意参与并与之联系在一起的愿景。
有理由相信,阶跃Step系列,以及中国的大模型们,都会因为卓越的技术实力和不懈的创新追求,越来越熠熠生辉。
One More Thing
上个月,智源研究院推出辩论平台 ,旨在通过引入模型辩论这一竞争机制对大模型能力评估提供新的度量标尺。
和大模型竞技场玩法有点类似,就是俩模型一个正方一个反方,双盲测试,辩论完后用户投票。
然后才揭晓正反双方都是谁。
模型辩论,主要靠的是信息理解、知识整合、逻辑推理、语言生成和对话能力。
当然了,同时还能测复杂语境中信息的处理深度和迁移应变能力,反映其学*与推理的进步水平。
浅玩了一下,有些议题还蛮有意思。
比如“博物馆着火,只能救一个,救猫还是救《蒙娜丽莎》”这个议题。
俩模型吵到后面,“猫有九条命”的话都说出来了,笑死。
最后反复投了几次,Step2大胜o1。
看来它辩论能力也很强呀……







- 12024年最建议买的车,配置多达五六个,价格区间混乱花费大量时间进行
- 21.8t是什么意思,是怎么换算的,这些都是购车前必须弄清楚的问题
- 3七座车大全,它们各具特色和功能,成为了汽车爱好者们热议的焦点
- 4国产奔驰glk300报价,在车型对比上,GLK与某些轿车有所不同
- 5口碑好的新能源汽车品牌,紧凑型车中独树一帜,成为众多追求品质消费
- 6轻骑铃木gt125,这款车性能出众,不过也伴随不少让人烦恼的问题
- 7适合女生开的车10万左右自动挡,她们在选车时更倾向于关注外观和内
- 8雪佛兰科鲁兹颜色,方案丰富多样,不同车型的配置和性能自然有所区别
- 92024年最建议买的suv车,消费者必须充分了解相关信息,以便作出明智
- 10宝马x52. 0[53 01差别,各车型分辨及选购指南
- 11凯越最新报价,入门级车型堪称性价比之选
- 12帝豪gs质量怎么样,销量表现不错,其外观与品质均颇受好评
- 13两万以下二手车,在购买过程中,我们必须全面考虑车辆的各种因素
- 14机械革命无界 14X 配置上新:R78845HS + 32G + 1T 售 4699 元
- 15天津二手伊兰特,它已经成为了现代品牌在中国市场成功的典范

推荐



最新标签
 (24小时内及时处理)
(24小时内及时处理)