
AI 系统互连技术的新选择:光互连
在现代 AI 系统中,使用 PCIe 将加速器连接在一起已经太慢了。出于这个原因, 和 AMD 使用 和 等专用互连 ,但在这些链路推动的超过 900 GB/秒的速度下,铜线只能提供有限的支持。
于是,光互连,正在成为很多人的新选择。在博通看来,核心光互连有三种:
垂直腔面发射激光器(VCSEL) 是整个行业光学 AI 互连技术的主力。其低功耗和低成本使其成为数据通信和传感应用的理想选择。唯一的限制是它在较短的链路距离内运行效果最佳。
电吸收调制激光器 (EML) 非常适合扩展到更远距离和数十万甚至数百万个单元的 AI 系统。该技术在非常高的带宽下提供更好的性能,并且通常是第一个以下一代数据速率实现批量部署的技术。
共封装光学器件(CPO)是一种将高速硅光子学异质集成到专用集成电路上的先进技术,旨在解决下一代带宽和功率挑战。我们认为这项新技术将为未来几代人工智能系统提供功率和成本领先优势,并支持大规模人工智能网络的基础设施。
围绕着这三个方向,芯片厂商们各出奇招,半导体行业观察在早前的报道《PCIe,新*》中们阐述了PCIe行业对光的追求。现在,芯片巨头更新了更多的光互连新方案,让我们看一下他们方案有何异同。
博通的光学封装新尝试
光学系统部门营销和运营副总裁 Mehta 表示,在高端集群中,铜线只能传输约三到五米,信号就会开始减弱。随着串行器反序列化器 () 的速度超过 /秒,铜线的传输距离只会越来越短。
答案正如您所料,就是放弃铜线,转而采用光缆——尽管这样做会增加功耗。 估计,如果在其 NVL72 系统中使用光缆而非铜线,则每机架功耗将增加 20 千瓦——而目前的额定功耗为 120 千瓦。
虽然单个收发器消耗的电量并不多——据 Mehta 称,每个收发器仅消耗 13 到 15 瓦电能——但当你谈论多个交换机,每个交换机有 64 或 128 个端口时,这些电能就会迅速增加。“如果需要扩大规模以达到更高的覆盖范围,从而实现光纤连接,你将需要 10 倍的带宽,而这在这种模式下是无法实现的,”他在本周的 Hot Chips 大会上发表演讲时解释道。
相反,博通目前正在尝试将光学器件直接封装到 GPU 本身中。
共封装光学 (CPO) 是博通多年来一直在探索的东西。在2022 年,这家网络巨头就展示了其 交换机,该交换机提供了 50/50 的传统电气接口和共封装光学接口的混合。
2023 年初,博通又演示了第二代 CPO 交换机,带宽是原来的两倍,达到 51.2Tbit/秒,它将八个 6.4Tbit/秒的光学引擎连接到 5 ASIC,提供 64 个纯 /秒端口。更重要的是,Mehta 声称,通过这样做,博通能够将每个端口的功耗降低到原来的三分之一,即每端口 5 瓦。

如前文所说,博通一直是CPO的追随者,为什么是 CPO?在博通看来,随着 AI 系统的发展,带宽和组件数量不断增加。与此同时,光学器件的成本也不断上升。我们的解决方案是集成到硅光子学中,这样我们就可以将更多组件放到单个芯片上。在半导体历史上,这是降低成本的有效方法。
另一个好处是光学器件可以与核心芯片放在一个通用封装中。这种布局消除了 ASIC 和光学器件之间复杂的电气通道。典型的 800G 可插拔收发器每条链路消耗约 16 瓦。例如博通早前已经商用的 51.2-Tbps CPO 以太网交换机系统把该光链路功率降低到 5 瓦,比当今的典型部署节省 70%。更令人印象深刻的是,当光链路迁移到 1.6T 时,它可以扩展并提供更好的效率,通常可插拔收发器的功耗为 25 瓦,而 CPO 的功耗为 8 瓦。这对于节能和光学器件来说都是一件大事。
第三个主要好处是可靠性增强。可插拔收发器的故障率约为 2%。通过将更多组件集成到芯片中,CPO 可提高可靠性。我们不是将激光器直接集成在硅片上,而是将激光系统作为系统中可插拔且易于更换的组件。其他一切都建立在具有悠久可靠性历史的核心硅片技术之上。
基于这个思考,在本周的Hot Chips 大会上,博通披露了其最新尝试,即将其中一个光学引擎与 GPU 封装在一起,为每个芯片提供大约 1.6TB/秒的总互连带宽(即每个方向 6.4Tbit/秒或 800GB/秒),同时展示“无错误性能”,Mehta 解释道。这使得它与 的下一代 结构处于同一水平,后者将与 一代同时发布,后者将通过铜线为每个 GPU 提供 1.8TB/秒的总带宽。

需要明确的是,目前还没有一款 A100 或 搭载 光学互连芯片。至少我们并不知道有这样的芯片。 实验中的 GPU 实际上只是一个旨在模拟真实芯片的测试芯片。为此,它使用台积电的晶圆基板芯片 (CoWoS) 封装技术将一对 HBM 堆栈粘合到计算芯片上。但是,虽然芯片逻辑和内存位于硅中介层上,但 的光学引擎实际上位于基板上。
这很重要,因为基本上每个使用 HBM 的高端加速器都依赖于 CoWoS 风格的先进封装——即使 自己的芯片不需要它。
据 Mehta 介绍,这种连接可以在短短 8 个机架中支持 512 个 GPU,充当单一扩展系统。

现在,你可能会想,亚马逊、谷歌、Meta 和一大批数据中心运营商不是已经部署了 10000 个或更多 GPU 的集群了吗?他们当然在部署,但这些集群属于横向扩展类别。工作通过相对较慢的以太网或 网络分布到最多有 8 个 GPU 的系统。
Mehta 谈论的是扩展系统,比如 的 NVL72。只不过,该架构不是将 72 个 GPU 组合成一个大 GPU,而是速度足够快,可以扩展到数百个 GPU 组成一个巨大的加速器。
除了将光学引擎的速度推至 6.4Tbit/秒以上之外,Mehta 还看到了在计算封装上拼接多个芯片的潜力。
英特尔的光互连新方案
除了博通以外,多年来,英特尔也一直在推进芯片到芯片的光学互连研究。
据介绍,公司长期以来一直处于硅光子学研究的前沿。在他们看来,这是扩大计算机处理器之间通信带宽的下一个前沿。该技术将硅集成电路与半导体激光器相结合,以比传统电子产品更快的速度在更长的距离上传输数据。它不仅支持更高带宽的数据传输,还为软件配置的计算和存储资源访问铺平了道路。它还允许软件定义的基础设施与分散数据中心的硬件和软件资源分离。
英特尔认为,对硅光子学的需求比以往任何时候都更加迫切,因为日益强大的人工智能模型的需求正在给现有的数据中心基础设施带来巨大压力。随着人工智能模型变得越来越强大,它们需要的数据也越来越多,而现有的芯片互连几乎无法满足需求。因此,英特尔表示,迫切需要硅光子学来支持人工智能的发展。
英特尔解释称,尽管现有的电气 I/O 技术(目前大多数芯片互连的基础)可以支持高带宽密度,但它们只能在 1 米或更短的极短距离内实现这一目标。虽然可以使用可插拔光收发器模块来扩大这一距离,但这会导致成本过高和能耗过高,无法满足 AI 工作负载的需求。
于是,我们就看到了英特尔首款 OCI 。在上带来了他们速度达到4Tbps的光学新方案展示。
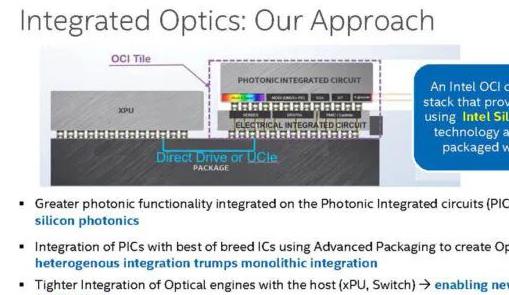
其实,该技术最是在 2024 年光纤通信大会 (OFC) 上披露。当时,英特尔集成光子解决方案 (IPS) 集团展示了业界最先进、首款全集成光计算互连 (OCI) 芯片,该芯片与英特尔 CPU 共同封装并运行实时数据。
在英特尔看来,公司的 OCI 芯片通过在数据中心和高性能计算 (HPC) 应用的新兴 AI 基础设施中实现共同封装的光学输入/输出 (I/O),代表了高带宽互连的一次飞跃。
据英特尔介绍,首款 OCI 芯片旨在支持 64 个通道,每个通道的数据传输速度为 32 Gbps,最长可达 100 米,有望满足 AI 基础设施对更高带宽、更低功耗和更长传输距离的日益增长的需求。它支持未来 CPU/GPU 集群连接和新型计算架构的可扩展性,包括一致的内存扩展和资源分解。
基于 AI 的应用程序在全球范围内的部署越来越多,大型语言模型 (LLM) 和生成式 AI 的最新发展正在加速这一趋势。更大、更高效的机器学* (ML) 模型将在满足 AI 加速工作负载的新兴需求方面发挥关键作用。未来 AI 计算平台的扩展需求正在推动 I/O 带宽和更长距离的指数级增长,以支持更大的处理单元 (CPU/GPU/IPU) 集群和架构,并实现更高效的资源利用率,例如 xPU 分解和内存池化。
电气 I/O(即铜线连接)支持高带宽密度和低功耗,但仅提供约一米或更短的短距离。数据中心和早期 AI 集群中使用的可插拔光收发器模块可以增加覆盖范围,但成本和功率水平无法满足 AI 工作负载的扩展要求。同封装的 xPU 光 I/O 解决方案可以支持更高的带宽,同时提高功率效率、降低延迟并增加覆盖范围——这正是 AI/ML 基础设施扩展所需要的。
英特尔打了一个比方,帮助说明当今的电气 I/O 互连与其新的 OCI 芯片之间的区别。它将用于支持当今 AI 应用程序的 CPU/GPU 集群比作“同一街区的房屋”。住在这些房屋中的人们可以轻松地挨家挨户地与邻居交流,但这种交流在街区之外是不可能实现的。
“像英特尔 OCI 芯片这样的光学 I/O 解决方案为这些邻居提供了一辆摩托车,使他们能够一次运送更多货物,运送到街区外其他房屋的距离更长,而无需消耗太多能源。”“这种水平的性能提升正是新兴人工智能扩展所需要的。”英特尔解释说。
完全集成的 OCI 芯片组利用英特尔经过现场验证的硅光子技术,将包含片上激光器和光放大器的硅光子集成电路 (PIC) 与电子 IC 集成在一起。在 OFC 上展示的 OCI 芯片组与英特尔 CPU 共同封装,但也可以与下一代 CPU、GPU、IPU 和其他片上系统 (SoC) 集成。
首个 OCI 实现支持高达每秒 4 兆兆位 (Tbps) 的双向数据传输,与外围组件互连高速通道 (PCIe) Gen5 兼容。实时光链路演示展示了两个 CPU 平台通过单模光纤 (SMF) 跳线之间的发射器 (Tx) 和接收器 (Rx) 连接。CPU 生成并测量了光误码率 (BER),演示展示了单根光纤上 8 个波长间隔为 200 千兆赫 (GHz) 的 Tx 光谱,以及 32 Gbps Tx 眼图,显示了强大的信号质量。
当前的芯片组支持 64 个 32 Gbps 数据通道,每个方向可达 100 米(但由于飞行时间延迟,实际应用可能仅限于数十米),使用八对光纤,每对光纤承载八个密集波分复用 (DWDM) 波长。该共封装解决方案还具有出色的节能效果,每比特仅消耗 5 皮焦耳 (pJ),而可插拔光收发器模块的能耗约为 15 pJ/比特。这种超高效率对于数据中心和高性能计算环境至关重要,有助于解决 AI 不可持续的功耗需求。
展望未来,英特尔希望将其扩展到更快的波特率以及更多波长。它还可以通过在未来提供更多光纤来扩展。
写在最后
除了博通和英特尔之外,很多公司也在光互连上发力,例如在 SC23 上,Ayar Labs展示了其 共封装光学解决方案及其 光源的最新进展。该技术允许将光学器件直接插入芯片封装中,从而摆脱 PCB 和长电气走线的限制。许多其他硅光子学初创公司也承诺提供类似的功能,其中包括 和 AI,它们的产品正处于不同的开发和生产阶段。
虽然我们目前还不知道 AMD 有采用共同封装光学器件的 GPU 或 APU,但今年春天 AMD 首席技术官 Mark 和高级副总裁 Sam 讨论了这种芯片的可能性。 直言,未来,UCIe 等标准可能会让第三方制造的芯片进入 AMD 封装。他提到硅光子互连(一种可能缓解带宽瓶颈的技术)有潜力将第三方芯片引入 AMD 产品。
同时指出,如果没有低功耗的芯片间互连,这项技术就不可行。
“你需要使用光学器件是因为你需要巨大的带宽。因此,你需要低能耗才能实现这一点,而封装芯片是获得最低能耗接口的方法,”他解释说,并补充说,他认为向共封装光学器件的转变“即将到来”。







- 1别克英朗gt优惠,在选购汽车时,外观往往是人们首要考虑的因素
- 22024公认最好纯电动车排行榜,需特别留意车企对于三电系统的质保规
- 3qq车价格,一次普通的保养只需花费两三百元即可
- 4长时间不开的车怎么保养,这可是大错特错,简单的准备能避免很多麻烦
- 5车电瓶亏电怎么恢复电量,一个小电池出了问题,整个电池的功能都可能
- 64s是什么意思,这个缩写在不同的领域有着不同的含义
- 7买了电动汽车后悔死了,这些特点让它成为了市场中的一股力量
- 8第一批比亚迪车主换电池,这无疑是一笔不小的负担
- 9电瓶亏电后一直充不满,要是不及时补充,电压就可能不够用
- 10抚顺到昆明路程查询,走哪条路线最合适,还有时刻表得安排得妥当
- 11宝马X5保养 次多少钱,行驶的距离越长,油耗成本也会随之增加
- 12腾翼c30 2012款,具有独特风格,在价格上它具有明显优势
- 13汽车电瓶没电的四种情况,这种情况有很多应对的小技巧,咱们得好好学
- 14南京旅游必去的地方,那就跟着咱们走一遭,好好看看
- 15车打不着但是仪表盘亮,原因可多了去了,我慢慢给你们说说

推荐



最新标签
 (24小时内及时处理)
(24小时内及时处理)