
o1突发内幕曝光?谷歌更早揭示原理,大模型光有软件不存在护城河
明敏 发自 凹非寺
量子位 | 公众号
发布不到1周,最强模型o1的护城河已经没有了。
有人发现,谷歌一篇发表在8月的论文,揭示原理和o1的工作方式几乎一致。

这项研究表明,增加测试时(test-time)计算比扩展模型参数更有效。
基于论文提出的计算最优(-)测试时计算扩展策略,规模较小的基础模型在一些任务上可以超越一个14倍大的模型。
网友表示:
这几乎就是o1的原理啊。
众所周知,奥特曼喜欢领先于谷歌,所以这才是o1抢先发版的原因?
有人由此感慨:
确实正如谷歌自己所说的,没有人护城河,也永远不会有人有护城河。
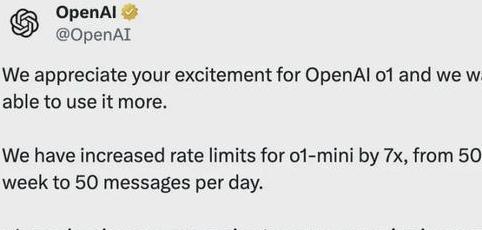
就在刚刚,将o1-mini的速度提高7倍,每天都能使用50条;o1-则提到每周50条。
计算量节省4倍
谷歌这篇论文的题目是:优化LLM测试时计算比扩大模型参数规模更高效。
研究团队从人类的思考模式延伸,既然人面对复杂问题时会用更长时间思考改善决策,那么LLM是不是也能如此?
换言之,面对一个复杂任务时,是否能让LLM更有效利用测试时的额外计算以提高准确性。
此前一些研究已经论证,这个方向确实可行,不过效果比较有限。
因此该研究想要探明,在使用比较少的额外推理计算时,就能能让模型性能提升多少?
他们设计了一组实验,使用PaLM2-S*在MATH数据集上测试。
主要分析了两种方法:
(1)迭代自我修订:让模型多次尝试回答一个问题,在每次尝试后进行修订以得到更好的回答。
(2)搜索:在这种方法中,模型生成多个候选答案,
可以看到,使用自我修订方法时,随着测试时计算量增加,标准最佳N策略(Best-of-N)与计算最优扩展策略之间的差距逐渐扩大。
使用搜索方法,计算最优扩展策略在初期表现出比较明显优势。并在一定情况下,达到与最佳N策略相同效果,计算量仅为其1/4。
在与预训练计算相当的FLOPs匹配评估中,对比PaLM 2-S*(使用计算最优策略)一个14倍大的预训练模型(不进行额外推理)。
结果发现,使用自我修订方法时,当推理tokns远小于预训练时,使用测试时计算策略的效果比预训练效果更好。但是当比率增加,或者在更难的问题上,还是预训练的效果更好。
也就是说,在两种情况下,根据不同测试时计算扩展方法是否有效,关键在于提示的难度。
研究还进一步比较不同的PRM搜索方法,结果显示前向搜索(最右)需要更多的计算量。
在计算量较少的情况下,使用计算最优策略最多可节省4倍资源。
对比的o1模型,这篇研究几乎是给出了相同的结论。
o1模型学会完善自己的思维过程,尝试不同的策略,并认识到自己的错误。并且随着更多的强化学*(训练时计算)和更多的思考时间(测试时计算),o1 的性能持续提高。
不过更快一步发布了模型,而谷歌这边使用了PaLM2,在上还没有更新的发布。
网友:护城河只剩下硬件了?
这样的新发现不免让人想到去年谷歌内部文件里提出的观点:
我们没有护城河,也没有。开源模型可以打败。
如今来看,各家研究速度都很快,谁也不能确保自己始终领先。
唯一的护城河,或许是硬件。
(所以马斯克哐哐建算力中心?)
有人表示,现在英伟达直接掌控谁能拥有更多算力。那么如果谷歌/微软开发出了效果更好的定制芯片,情况又会如何呢?
值得一提的是,前段时间首颗芯片曝光,将采用台积电最先进的A16埃米级工艺,专为Sora视频应用打造。
显然,大模型战场,只是卷模型本身已经不够了。
参考链接:







- 1别克英朗gt优惠,在选购汽车时,外观往往是人们首要考虑的因素
- 22024公认最好纯电动车排行榜,需特别留意车企对于三电系统的质保规
- 3qq车价格,一次普通的保养只需花费两三百元即可
- 4长时间不开的车怎么保养,这可是大错特错,简单的准备能避免很多麻烦
- 5车电瓶亏电怎么恢复电量,一个小电池出了问题,整个电池的功能都可能
- 64s是什么意思,这个缩写在不同的领域有着不同的含义
- 7买了电动汽车后悔死了,这些特点让它成为了市场中的一股力量
- 8第一批比亚迪车主换电池,这无疑是一笔不小的负担
- 9电瓶亏电后一直充不满,要是不及时补充,电压就可能不够用
- 10抚顺到昆明路程查询,走哪条路线最合适,还有时刻表得安排得妥当
- 11宝马X5保养 次多少钱,行驶的距离越长,油耗成本也会随之增加
- 12腾翼c30 2012款,具有独特风格,在价格上它具有明显优势
- 13汽车电瓶没电的四种情况,这种情况有很多应对的小技巧,咱们得好好学
- 14南京旅游必去的地方,那就跟着咱们走一遭,好好看看
- 15车打不着但是仪表盘亮,原因可多了去了,我慢慢给你们说说

推荐



最新标签
 (24小时内及时处理)
(24小时内及时处理)