
英伟达NVLM 1.0引领多模态AI变革,媲美GPT-4o
科技媒体 昨日(9 月 20 日)发布博文,报道了英伟达()最新发布的论文,介绍了多模态大语言模型系列 NVLM 1.0。
多模态大型语言模型(MLLM)
多模态大型语言模型(MLLM)所创建的 AI 系统,能够无缝解读文本和视觉数据等,弥合自然语言理解和视觉理解之间的差距,让机器能够连贯地处理从文本文档到图像等各种形式的输入。
多模态大型语言模型在图像识别、自然语言处理和计算机视觉等领域拥有广阔应用前景,改进人工智能整合和处理不同数据源的方式,帮助 AI 朝着更复杂的应用方向发展。
英伟达 NVLM 1.0
NVLM 1.0 系列包括 NVLM-D、NVLM-X 和 NVLM-H 三种主要架构。每个架构都结合先进的多模态推理功能与高效的文本处理功能,从而解决了以往方法的不足之处。
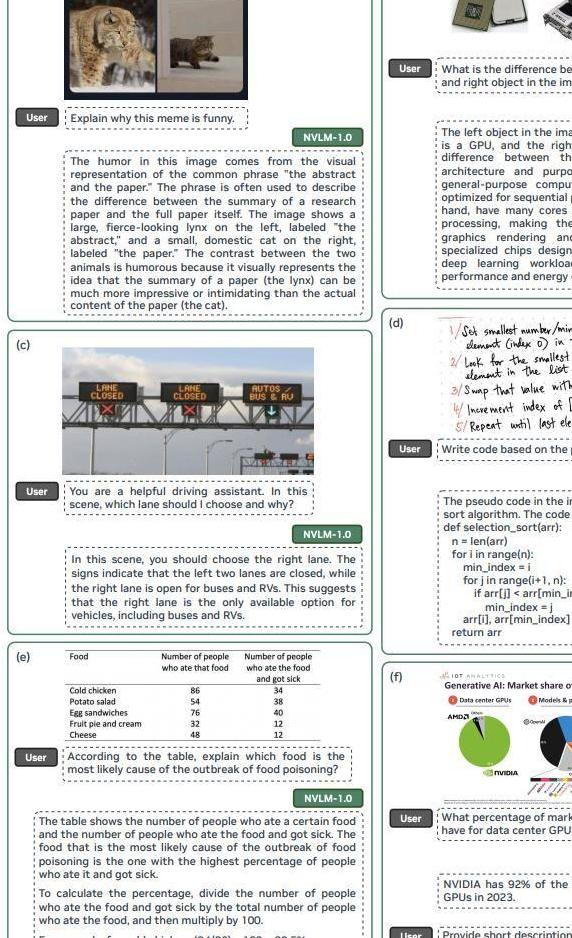
NVLM 1.0 的一个显著特点是在训练过程中加入了高质量纯文本监督微调(SFT)数据,这使得这些模型在视觉语言任务中表现出色的同时,还能保持甚至提高纯文本性能。
研究团队强调,他们的方法旨在超越 GPT-4V 等现有专有模型和 等开放式替代模型。
NVLM 1.0 模型采用混合架构来平衡文本和图像处理:
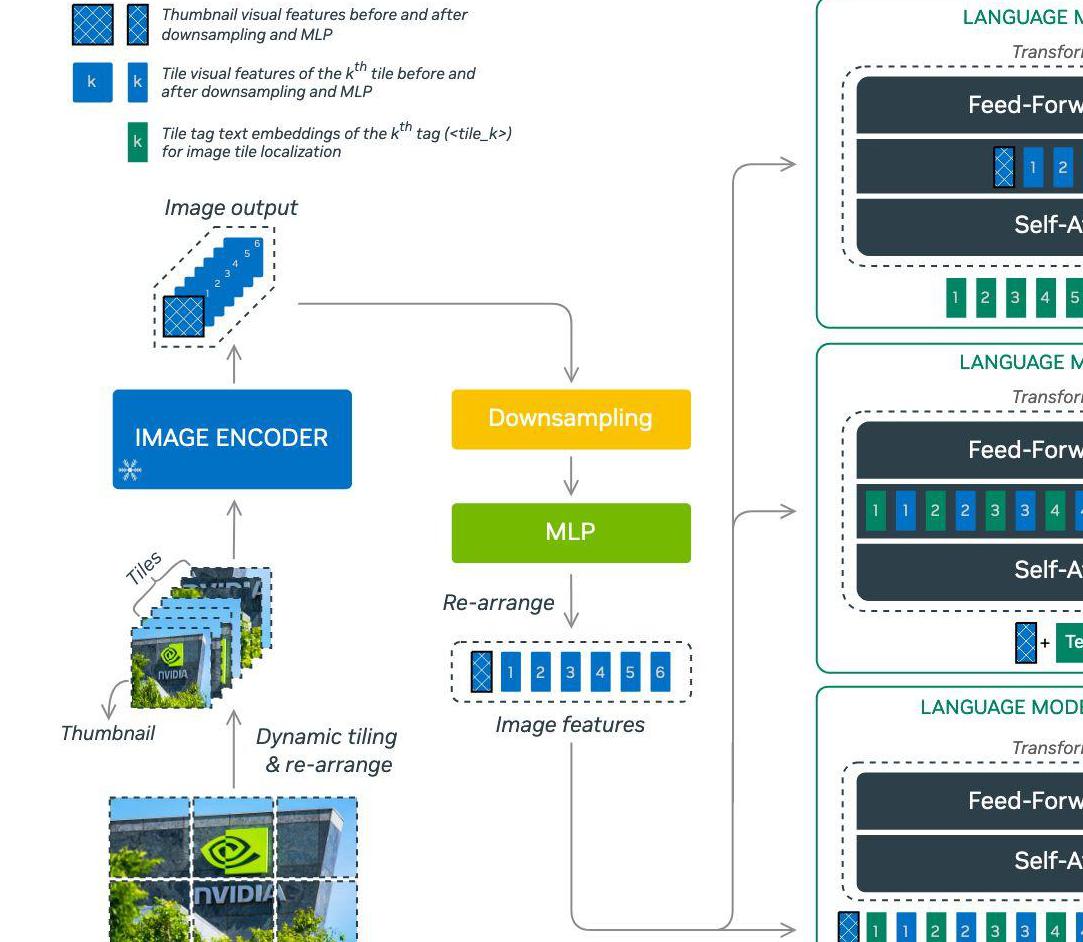
这些模型结合了高分辨率照片的动态平铺技术,在不牺牲推理能力的情况下显著提高了 OCR 相关任务的性能。
性能
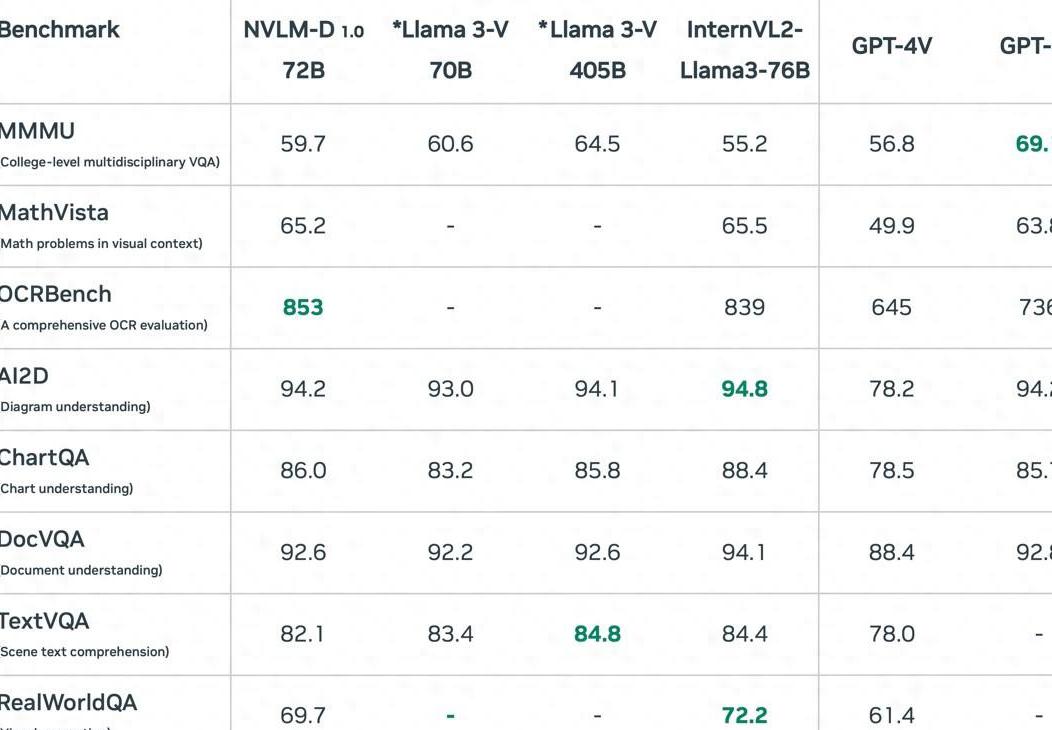
在性能方面,NVLM 1.0 模型在多个基准测试中取得了令人印象深刻的成绩。

研究的主要发现之一是,NVLM 模型不仅在视觉语言任务中表现出色,而且还保持或提高了纯文本性能,这是其他多模态模型难以达到的。
例如,在基于文本的推理任务(如 MMLU)中,NVLM 模型保持了较高的准确率,在某些情况下甚至超过了纯文本模型。
想象一下在自动驾驶汽车中的应用场景。NVLM 1.0 可以通过摄像头实时获取道路信息,并与车辆导航系统进行语言沟通。
它不仅能识别交通标志,还能理解复杂路况下的人类指令,例如“如果前方有施工,请寻找替代路线”。这得益于其强大的视觉-语言处理能力以及出色的文本推理能力,使得自动驾驶更加智能、安全、可靠。
小结
英伟达开发的 NVLM 1.0 模型代表了多模态大型语言模型的重大突破,该模型通过在多模态训练中集成高质量文本数据集,并采用动态平铺和高分辨率图像平铺标记等创新架构设计,解决了在不牺牲性能的前提下平衡文本和图像处理的关键难题。
NVLM 系列模型不仅在视觉语言任务方面超越了领先的专有系统,而且还保持了卓越的纯文本推理能力,让多模态人工智能系统的发展又向前迈进一大步。







- 1别克英朗gt优惠,在选购汽车时,外观往往是人们首要考虑的因素
- 22024公认最好纯电动车排行榜,需特别留意车企对于三电系统的质保规
- 3qq车价格,一次普通的保养只需花费两三百元即可
- 4长时间不开的车怎么保养,这可是大错特错,简单的准备能避免很多麻烦
- 5车电瓶亏电怎么恢复电量,一个小电池出了问题,整个电池的功能都可能
- 64s是什么意思,这个缩写在不同的领域有着不同的含义
- 7买了电动汽车后悔死了,这些特点让它成为了市场中的一股力量
- 8第一批比亚迪车主换电池,这无疑是一笔不小的负担
- 9电瓶亏电后一直充不满,要是不及时补充,电压就可能不够用
- 10抚顺到昆明路程查询,走哪条路线最合适,还有时刻表得安排得妥当
- 11宝马X5保养 次多少钱,行驶的距离越长,油耗成本也会随之增加
- 12腾翼c30 2012款,具有独特风格,在价格上它具有明显优势
- 13汽车电瓶没电的四种情况,这种情况有很多应对的小技巧,咱们得好好学
- 14南京旅游必去的地方,那就跟着咱们走一遭,好好看看
- 15车打不着但是仪表盘亮,原因可多了去了,我慢慢给你们说说

推荐



最新标签
 (24小时内及时处理)
(24小时内及时处理)