
OpenAI重磅发布交互界面canvas,让ChatGPT成为写作和编程利器
机器之心报道
机器之心编辑部
刚刚融资,就迫不及待开始证明自己了。
今日凌晨, 宣布推出类似 的 的应用 ,并称「这是一种使用 写作和编程的新方式」。
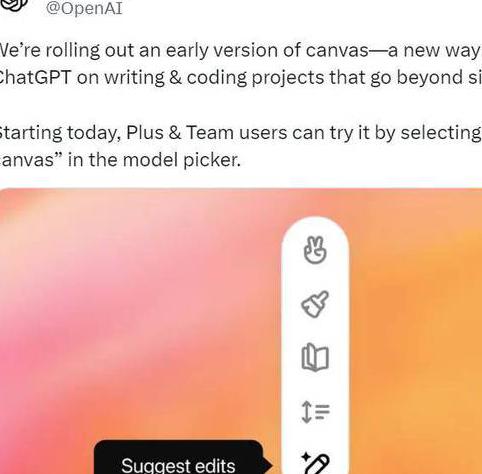
在 中试过 的朋友都知道,这能极大提升 LLM 输出结果的表现力,其支持输出文本文件、代码、网页、SVG 等等。此前风靡一时的「汉语新解」便是基于 的 功能。但让 用户感到遗憾的是, 上线三个多月了, 一直没有跟进,以至于一些开发者自行开发发布了自己的开源版本。
现在,用户的呼声终于获得了响应,于是纷纷点赞。也有人开玩笑地表示 这是打不过 便加入。
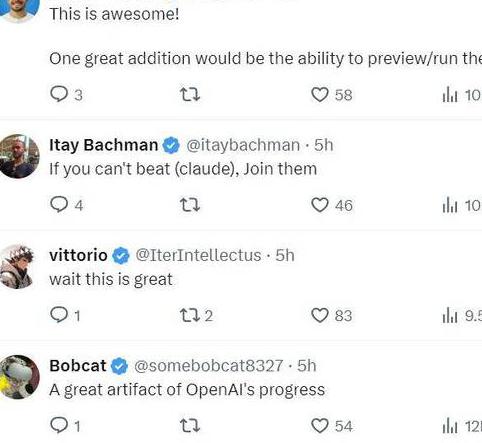
已有用户分享了自己使用 的惊喜成果,比如用户 @ 分享自己让 使用 创建超立方体查看器过程:
在 这个界面,你可以与 一起完成写作和编码项目,而不再局限于简单的聊天。 是一种新的交互方式,也是 推出 以来的首个重大视觉界面更新。
会在单独的窗口中打开,方便用户与 一起协作完成项目。 的 Beta 版本为用户提供了一种全新的合作方式:你不仅能够通过对话进行创作,还能与 成为并肩作战的伙伴,一起创造和完善。
由 GPT-4o 支持,在 Beta 期间可以在模型选择器中手动选择。不过,现在 Beta 版本只提供给 Plus 与团队用户。企业和教育用户将在下周获得访问权限。 免费用户需要等到 正式发布后才能使用。
我们先一睹 有哪些惊艳之处。
与 更好地协作
和 聊天对于我们来说已经是十分简便的信息获取方式,这也包括写作与编码。不过当你想要及时对写作内容或者编码内容进行修改时,对话方式可能就显得力不从心了。
的出现就是为了解决这个难题。
在这个新的界面中,你可以通过高亮的方式,告诉 具体需要关注什么,让它更精准地理解你的用意。这就类似于编辑,你可以在全部上下文中具体地提出反馈和建议。
你的调整方式也十分便捷,直接编辑代码或文本都不成问题。你的项目,你做主。 还提供了快捷菜单,可以让 帮你调整文本长度、调试代码,或者快速执行其他实用操作。如果想要之前的版本,一键返回即可恢复。
写作快捷操作,图源:
当 发现某个场景中 能帮上忙时,它会自动打开。你也可以在提示中直接加一句「使用 」,这样 就会切换到 界面,帮助你更方便地处理现有项目。
,时长
00:51
的编程能力
代码是一个迭代过程,但是在聊天之中,很难跟踪代码的改进过程。 让我们可以更轻松地跟踪和理解 的修改过程, 也承诺「计划继续提升这类编辑过程的透明度」。
目前提供了以下编程快捷操作:
将模型训练为协作伙伴
的研究团队对 GPT-4o 进行了训练,以使其能够作为创意合作伙伴进行协作。该模型知道何时打开 ,何时进行目标性编辑,以及何时需要完全重写。同时,它还能够理解更广泛的上下文,从而提供精准的反馈和建议。
为了支持这一点,研究团队开发了以下核心行为:
通过 20 多项自动化内部评估来衡量进展,并使用了新颖的合成数据生成技术,例如从 的 o1- 中提取输出,来对模型进行核心行为的后训练。这种方法能够快速应对写作质量和新的用户交互需求,从而无需依赖人工生成的数据。
对研发团队来说,一个关键挑战是何时触发 。 训练模型在像「写一篇关于咖啡豆历史的博客文章」这样的提示词下打开 ,同时避免对像「帮我做一道新的晚餐食谱」这样的一般问答任务进行过度触发。
在写作任务中,他们优先改进了「正确触发」的情况(以牺牲「正确不触发」为代价),达到了 83%,相较于作为基线的零样本提示词式 GPT-4o 有了显著提升。
值得注意的是,此类基线的质量对特定提示词非常敏感。不同的提示词可能导致基线在表现不佳的同时,呈现不同的错误分布。
例如,在编码和写作任务中会出现「均匀地不准确」情况,导致不同类型的错误分布和表现不佳的形式。在编码方面, 有意让模型在触发方面偏向保守,以避免干扰高级用户的体验。之后, 也是承诺将继续根据用户反馈对其进行优化。
针对写作和编码任务, 改进了准确触发 决策边界的能力,分别达到了 83% 和 94%,相较于作为基线的零样本提示词式 GPT-4o 有明显提升。
第二个挑战在于对模型在触发 后的编辑行为进行调优,特别是决定何时进行目标性编辑,何时重写整个内容。
训练模型在用户通过界面明确选择文本时进行目标性编辑,否则就更倾向于重写内容。随着模型的不断完善, 的编辑行为也在持续演变。
针对写作和编码任务, 优先优化了 的目标编辑功能。带有 的 GPT-4o 在性能上比基线的提示词式 GPT-4o 高出 18%。
最后,训练模型生成高质量评论需要经过仔细的迭代。与前两个可以轻松适应自动化评估并辅以详细人工审查的案例不同,自动衡量评论的质量尤其具有挑战性。
因此, 使用人工评估来衡量评论的质量和准确性。他们所整合的 模型在准确性上比使用提示词指令的零样本 GPT-4o 高出 30%,在质量上高出 16%。
这表明合成训练显著提升了相较于带有详细指令说明的零样本提示词下的响应质量和行为表现。
目前仍处于早期测试阶段, 后续计划快速提升其功能。
至于它和 究竟谁更能赢得用户亲睐,就让我们拭目以待吧,相信刚拿了一大笔投资的 也应该不会让用户失望。







- 1别克英朗gt优惠,在选购汽车时,外观往往是人们首要考虑的因素
- 22024公认最好纯电动车排行榜,需特别留意车企对于三电系统的质保规
- 3qq车价格,一次普通的保养只需花费两三百元即可
- 4长时间不开的车怎么保养,这可是大错特错,简单的准备能避免很多麻烦
- 5车电瓶亏电怎么恢复电量,一个小电池出了问题,整个电池的功能都可能
- 64s是什么意思,这个缩写在不同的领域有着不同的含义
- 7买了电动汽车后悔死了,这些特点让它成为了市场中的一股力量
- 8第一批比亚迪车主换电池,这无疑是一笔不小的负担
- 9电瓶亏电后一直充不满,要是不及时补充,电压就可能不够用
- 10抚顺到昆明路程查询,走哪条路线最合适,还有时刻表得安排得妥当
- 11宝马X5保养 次多少钱,行驶的距离越长,油耗成本也会随之增加
- 12腾翼c30 2012款,具有独特风格,在价格上它具有明显优势
- 13汽车电瓶没电的四种情况,这种情况有很多应对的小技巧,咱们得好好学
- 14南京旅游必去的地方,那就跟着咱们走一遭,好好看看
- 15车打不着但是仪表盘亮,原因可多了去了,我慢慢给你们说说

推荐



最新标签
 (24小时内及时处理)
(24小时内及时处理)